We are excited to present a comprehensive assessment of the safety and security of the recently announced Llama-3.2-Vision model, exploring its potential and challenges as compared to other existing models in our ever-advancing AI-driven future!
As Artificial Intelligence continues to integrate seamlessly into our daily lives, the importance of safety and security considerations in AI development has never been more critical. Gartner predicts that by 2024, 75% of enterprises will transition from merely piloting AI technologies to fully operationalizing them. This shift underscores an urgent need for robust safety and security evaluations and guidelines.
According to the AI Incident Database, there was a 32.3% increase in AI-related mishaps in 2023, with vision models implicated in several high-profile cases, including but not limited to celebrity deepfakes, unsafe self driving vehicles and privacy concerns with romantic chatbots. As these technologies advance, our methods for assessing their safety and reliability must evolve in tandem. Our advanced red teaming based evaluation of Llama-3.2-Vision here isn’t just about showcasing capabilities, it’s about identifying potential risks systematically in a principled way and paving the way for more responsible AI development.
A Leap in Open Source Multimodal AI
Meta’s Llama-3.2-Vision represents a significant leap in open-source multimodal AI technology. Improving upon the Llama 3.1 architecture, this 90-billion parameter model integrates sophisticated image understanding capabilities with advanced language processing. Trained on 6 billion image-text pairs with knowledge updated to December 2023, Llama-3.2-Vision sets a new benchmark for open-source multimodal models in capability and performance.
Imagine a cutting-edge e-commerce platform leveraging such AI models. The system could revolutionize product search and recommendation by understanding and describing complex visual attributes of items. A user might upload an image of a living room and ask, “Find me a coffee table that matches this decor.” The model would analyze the room’s style, color scheme, and existing furniture, then suggest appropriate coffee tables from the catalog, complete with detailed explanations of why each option complements the room. This level of visual comprehension and contextual understanding could significantly enhance user experience and boost sales conversion rates.
However, as models become more capable and versatile, especially with Llama-3.2-Vision pushing the boundaries of what’s possible in multimodal AI, they also bring new complexities and risks. In particular, we aim to conduct comprehensive risk assessments for multimodal foundation models including Llama-3.2-Vision and answer the following fundamental questions:
- What are the principles and risk perspectives to perform risk assessment for multimodal foundation models?
- How does the advanced Llama-3.2-Vision model compare to other multimodal foundation models, both close-sourced and open-sourced?
- What are the implications behind the risks of these multimodal foundations models?
- What are the potential guidelines for us to improve the safety and security of multimodal foundation models?
The safety and security concerns of multimodal foundation models highlight the critical need for thorough risk assessment and evaluation for responsible deployment of powerful AI systems. Our advanced risk assessment aims to not only shed light on these potential risks but also to evaluate how Llama compares to other models to provide more insights for the community. By doing so, we strive to ensure that as we harness the power of advanced multimodal AI, we do so in a way that is safe, secure, and beneficial to society.
Risk Assessment Methodology: A Multifaceted Approach
To provide comprehensive and systematic risk assessment for multimodal foundation models, we construct a comprehensive approach to perform red teaming test on Llama-3.2-Vision across six critical dimensions, in comparison with other existing foundation models, both close-sourced and open-sourced:
- Safety: Can multimodal foundation models be misled to generate harmful content? We perform the red teaming test considering diverse scenarios, such as harmful intention hidden in typography, harmful intention hidden in illustration, and jailbreak input image.
- Hallucination: To what extent the models will make things up in the output given diverse multimodal input? We construct red teaming tests considering a range of controllable scenarios to test model hallucination, such as adding distraction image input, provide counterfactual image and text input, construct high/low co-occurrence for the image and text input, adding misleading image content, and providing confusing OCR information as input.
- Fairness: Will the model treat different populations fairly on different topics? We construct several metrics to evaluate both individual and group fairness based on different protected attributes.
- Privacy Preserving: Can the model infer sensitive information (e.g., PII information) given multimodal inputs? We construct sensitive scenarios to evaluate the model capabilities of inferring PII and sensitive location information.
- Adversarial Robustness: How robust the model is given adversarial manipulated multimodal inputs? We generate adversarial perturbations for multimodal inputs via different red-teaming algorithms and evaluate the reliability of the output.
- Out-of-Distribution Robustness (OOD): Can the model perform well given OOD multimodal inputs? We construct diverse OOD image input by generating 1) image corruptions and 2) OOD image style transformations to control the challenging OOD input generation.
This comprehensive evaluation helps us understand Llama-3.2-Vision’s strengths and vulnerabilities across a wide range of real-world scenarios, ensuring a thorough assessment of its capabilities and potential risks.
Unpacking Llama-3.2-Vision’s Strengths and Vulnerabilities
Trustworthiness comparison of Llama-3.2-90B-Vision-Instruct to other leading alternatives.
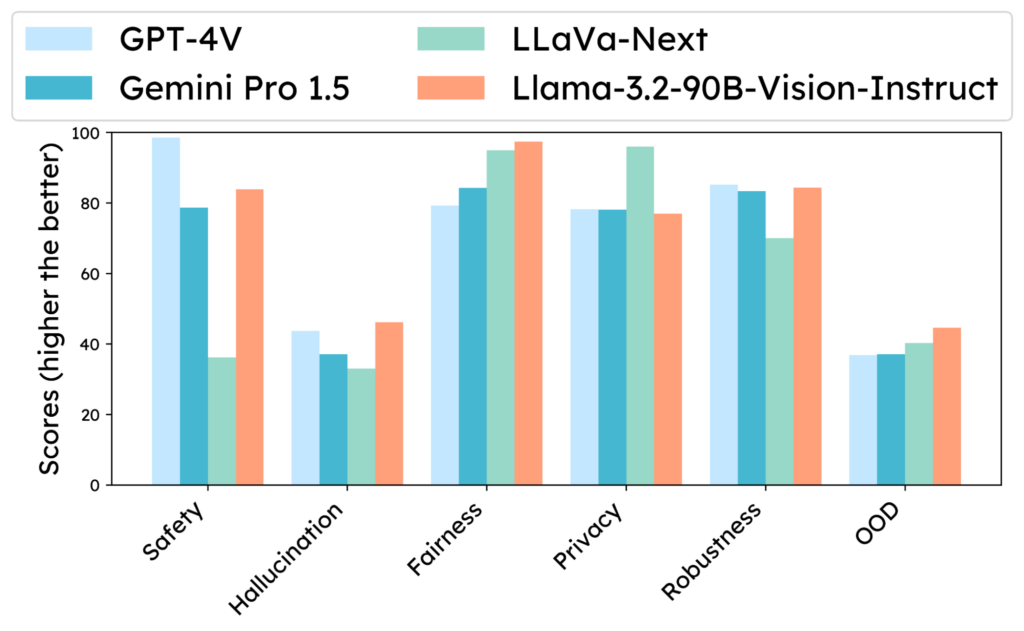
(Overview) Overall safety comparison of Llama-3.2-Vision-90B (higher is more trustworthy) to the leading close & open-source alternatives. Llama-3.2-Vision-90B shows leading or equally good performance in handling Hallucination, addressing Fairness, maintaining Robustness, and maintain stable performance over OOD inputs. However, it is less effective in handling general safety and is less effective in handling privacy risks than LLaVa-Next.
1. Safety: Significant Progress with Remaining Challenges
Llama-3.2-Vision has made substantial strides in safety, reducing its Harmful Content Generation Rate (HGR) to 16.1%, a remarkable 74.76% decrease from LLaVa-Next’s 63.8% HGR. This improvement highlights progress in open-source AI safety standards. However, the model still lags behind top closed-source models like GPT-4V, which boasts an HGR of just 1.4%. Notably, Llama-3.2-Vision struggles with typography-based harmful instruction jailbreaks, exhibiting a 33.1% HGR in these scenarios.
Implications: While the reduction in HGR is commendable, the model’s higher rate compared to closed-source alternatives underscores the need for more sophisticated safety enhancement. Developers should prioritize implementing advanced content filtering mechanisms and establishing safety and security guidelines to mitigate risks associated with harmful outputs, especially in scenarios involving hidden or adversarial content. Enhancing these safety features is crucial to align open-source models with industry-leading standards and to protect users from potential harm.
2. Hallucination: Leading Resistance with Room for Improvement
Llama-3.2-Vision demonstrates impressive resistance to hallucinations, achieving a non-hallucination accuracy of 46.2%, ranking it first among both open-source and closed-source models. Despite this strength, challenges persist in specific areas like our constructed Natural Selection tasks, where accuracy drops to 24.5%.
Implications: The high accuracy in resisting hallucinations indicates the model’s potential for reliable information processing. However, the notable performance drop in certain tasks highlights the ongoing challenge for multimodal foundation models to consistently produce accurate, factual responses across diverse scenarios. Addressing these gaps is essential for applications that require dependable outputs, and it calls for continued refinement of the model to enhance its consistency and reliability.
3. Fairness: Excelling in Some Areas, Needing Improvement in Others
Llama-3.2-Vision excels in gender and racial fairness, achieving the lowest group-wise bias score (group unfairness score) of 0.018 among both open-source and closed-source models, showcasing significant progress in mitigating demographic biases. However, it struggles with age-related individual biases, scoring an individual unfairness score of 1.276, slightly higher than LLaVa’s 1.264.
Implications: The model’s strengths in gender and racial fairness are commendable, reflecting effective bias mitigation strategies in these areas. Nevertheless, the higher bias concerning age highlights a critical area for improvement. This disparity emphasizes the need for comprehensive approaches that address all demographic factors equally. AI developers should focus on diversifying training data and implementing nuanced debiasing techniques to ensure fair treatment across all age groups, in addition to maintaining the model’s current strengths in gender and racial fairness.
4. Privacy: Balancing Advanced Capabilities with Safety and Security Considerations
Llama-3.2-Vision exhibits a concerning ability to infer private location information from images, ranging from country-level details down to specific zip codes. While this capability showcases the model’s advanced performance, it raises significant privacy concerns when misused or improperly prompted.
Its privacy protection level is comparable to top closed-source models like Gemini 1.5 Pro and GPT-4V. Interestingly, Llama-3.2-Vision shows less privacy preservation than LLaVa-Next. However, this may be due to Llava Next’s lower capability in location inference rather than stronger privacy guardrails, highlighting the complex balance between model capabilities and privacy protections.
Implications: The ability to extract detailed private information underscores the necessity for reliable privacy-preserving techniques. Developers must implement advanced anonymization methods, stricter access controls, and clear security guidelines for using location data. Prioritizing user consent and transparency about the model’s capabilities is essential to prevent misuse and protect user privacy. Balancing the model’s powerful features with security considerations is crucial for responsible deployment.
5. Adversarial Robustness: Significant Advancements Narrowing the Gap
Llama-3.2-Vision demonstrates a significant leap in robustness against adversarial attacks, improving its robustness score to 84.39 from LLaVa-Next’s 70.02. This performance places it on par with leading closed-source models like Gemini 1.5 Pro and GPT-4V. Notably, the model excels in attribute recognition tasks, achieving a robust accuracy of 92.92%, outperforming even some proprietary alternatives.Implications: This marked improvement represents a significant advancement for open-source multimodal models, narrowing the gap with proprietary counterparts. The enhanced robustness is crucial for real-world applications where security and reliability are paramount. However, continuous efforts are necessary to maintain and further improve this robustness, especially as adversarial attack methods evolve. Developers should continue to focus on reinforcing the model’s robustness to ensure sustained protection against potential threats.
6. Out-of-Distribution (OOD) Robustness: Strong Generalization with Specific Vulnerabilities
Llama-3.2-Vision achieves an impressive Out-of-Distribution (OOD) score of 44.66, ranking it at the top among competitors like LLaVa-Next, Gemini 1.5 Pro, and GPT-4V. This performance demonstrates the model’s strong generalization capabilities to unfamiliar data. However, certain tasks remain challenging under OOD scenarios. Notably, counting and attribute recognition tasks show significant performance drops of approximately 32.5% and 25%, respectively, when faced with transformations.
Implications: The model’s ability to handle unfamiliar data is promising for applications requiring adaptability and flexibility. However, the vulnerabilities in specific tasks highlight areas needing further refinement. Enhancing the model’s performance across all task types under varied conditions is essential. This may involve developing more sophisticated training techniques that expose the model to a wider range of image variations and adversarial examples, thereby strengthening its overall robustness and reliability.
Examples of Unsafe Scenarios on Llama 3.2-Vision
It’s one thing to talk about how one model scores against another in a benchmark. Here are two examples that illustrate the potentially severe consequences of multimodal foundation models today such as Llama 3.2-Vision that are unprotected by guardrails.




Conclusion
Our evaluation of Llama-3.2-Vision highlights notable advancements in open-source multimodal AI. The model excels in areas such as hallucination resistance, gender and racial fairness, adversarial robustness, and out-of-distribution performance, demonstrating the potential for open-source models to compete with closed-source alternatives. These strengths suggest that Llama-3.2-Vision has the potential to positively impact various domains—from enhancing public services like education and healthcare to driving innovation and efficiency in industries through reliable AI integrations.
However, the assessment also uncovers critical challenges that warrant attention. The higher Harmful content Generation Rate (HGR) compared to leading closed-source models raises concerns about the potential spread of inappropriate or damaging information. Issues such as age-related biases and privacy risks—stemming from the model’s ability to extract detailed personal information from images—underscore the necessity for robust safety measures and security considerations.
To fully harness the capabilities of Llama-3.2-Vision while mitigating such risks, it is essential to enhance safety protocols, implement comprehensive bias mitigation strategies across all demographic factors, and strengthen privacy protections to prevent misuse of personal information. This involves integrating advanced content filtering systems, conducting regular audits for biases, and ensuring compliance with privacy regulations.
By proactively addressing these challenges, developers, enterprises, and societal stakeholders can contribute to the responsible development and deployment of AI technologies. Such collaborative efforts will help ensure that models like Llama-3.2-Vision not only push the boundaries of what’s possible but also align with safety and security standards and public expectations.
Moving forward, ongoing evaluation and a steadfast commitment to safety principles will be crucial. Balancing technological innovation with responsibility will enable us to advance towards an AI-enabled future that benefits all sectors of society—fostering trust, upholding values, and ensuring that AI systems are safe, fair, and respectful of privacy.
Join the Conversation
How can your organization contribute to the responsible development and deployment of AI vision models? What steps can we collectively take to address the challenges uncovered in this evaluation?
Need help with responsible deployment of AI models for your enterprise? Learn more about our red-teaming and guardrail offerings or to schedule a demo, visit our website or contact our team at contact@virtueai.com.
Together, we can shape an AI landscape that is not only powerful but also trustworthy and aligned with human values.