One Security Solutionfor Your Entire AI Stack.
Fueled by award-winning research, our AI-native platform secures every agent, model, and app in your enterprise.
Internal Policy
3 total violations
Most Violated Policy
1 total violations
Most Violated Policy
1 total violations
AI Guardrail Activated
Response
Approval Rate
66.67%
5% from yesterday
Approval Rate
66.67%
5% from yesterday


The blueprint for high-performance AI security.
End-to-End
Agent Security.
AI agents are already in production: writing code and making autonomous decisions. Virtue AI keeps them secure and compliant, applying real-time guardrails and preventing drift across any environment.
From Research to
Real-World Control.
Our "DecodingTrust" paper defined AI risk assessment. Now, our research-to-product loop turns academic breakthroughs into enterprise defenses in days, not months.
Enterprise Speed.
Enterprise Compliance.
Accelerate AI, without accelerating risk. Virtue AI offers sub-10ms, multimodal guardrails with audit-ready compliance, full observability, and Shadow AI detection: all running on our purpose-built inference framework.
Easy to Integrate.
Easy to Deploy.
Virtue AI hooks into the agent frameworks and apps you already use (OpenAI, Google, LangChain, OpenClaw, Claude Code) and deploys wherever you need it: from SaaS to fully on-prem.
One platform. Total enforcement.
01 - AgentSuite-Red
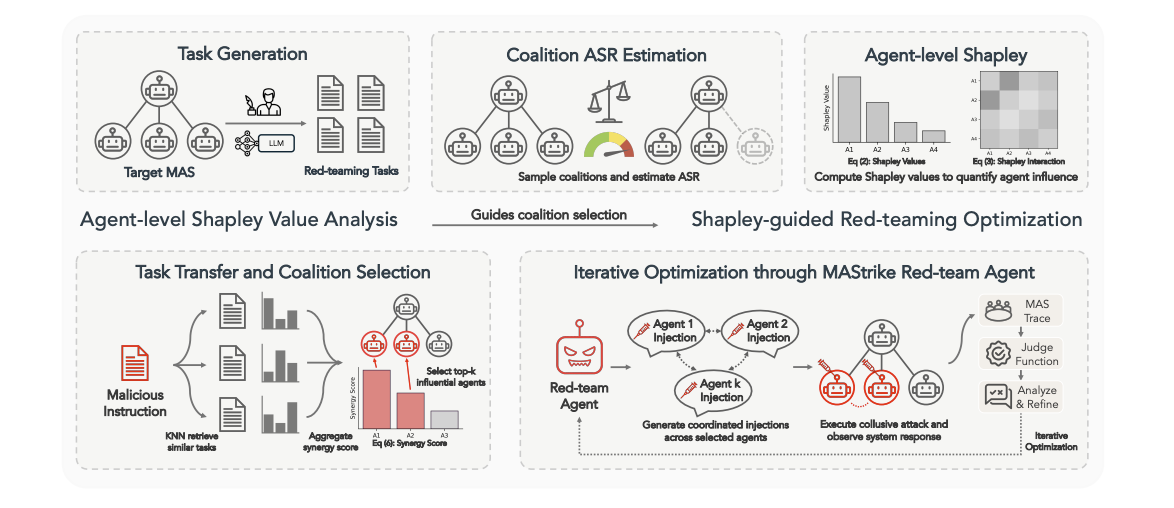
Agents operate in dynamic, stateful environments where small prompt manipulations escalate into costly incidents. AgentSuite-Red is the industry's first enterprise-scale, security-focused testing ground for agentic systems — red-teaming built for the way agents actually get exploited: direct prompt injection, indirect injection, and everything in between.
50+ sandboxed environments across 14 high-stakes domains including Databricks, Gmail, PayPal, ServiceNow, and Atlassian.
Support for every major framework — OpenAI Agents SDK, Claude SDK, Google ADK, LangChain, PocketFlow, and more — plus generic wrappers for any pre-built or custom agent.
Autonomous red-teaming agent with reusable attack skills, plus an Injection MCP Server that replays real attacks against any MCP-tool–using agent.
02 - AgentSuite-Blue
Agents don't just talk. They act. They call tools, move data, and trigger workflows on your behalf, so a single poisoned instruction can do serious damage. AgentSuite-Blue is your scalable security, governance, and compliance suite for agentic systems, powered by our purpose-built models and optimized for low latency,
MCP Guard: scan MCP tools and source code for hidden prompt injections, vulnerabilities, and data-leakage paths
Action Guard: monitor agent behavior as it happens and block malicious tool calls before they fire.
Shadow AI: you can't govern the AI you don't know about. Shadow AI surfaces the unsanctioned agents and apps running across your cloud and endpoints: who's using them, how often, and what they're actually doing.
Full Observability: analyze an agent's source code and capture the agent trajectory at runtime
03 - VirtueRed
As AI models are fine-tuned, retrained, and updated, security testing must evolve just as fast. Testing once a quarter (or even once a week) leaves gaps attackers can exploit. VirtueRed's continuous, automated, red-teaming uncovers hidden risks, validates behavior over time, and generates audit-ready evidence for security and compliance reviews.
100+ proprietary red-teaming algorithms for broad and deep testing
600+ attack vectors and 1000+ risk categories for comprehensive assessment
Multimodal evaluation across text, image, and video risk surfaces
Compliance-first alignment with frameworks such as EU AI Act, GDPR, OWASP LLM Top 10, NIST AI RMF, MITRE, and FINRA
On-Demand Security Reporting to support security, risk, and compliance reviews.
04 - VirtueGuard
Your AI makes one slip (toxic content, a leaked record, an unsafe image) and you have a regulatory violation or a PR crisis. VirtueGuard is Virtue AI's family of real-time safety models. Drop them into any application, agent, gateway, or RAG pipeline to block harmful content and enforce policy across modalities.
PolicyGuard: your rules, enforced in real time. Define policies in plain language, group them into guards, and call them from any application or gateway.
TextGuard Lite: fast text guardrail covering violence, hate, PII exposure, jailbreaks, and 12+ harm categories in 100+ languages
ImageGuard, VideoGuard, AudioGuard: security across every modality. Flagging unsafe, violent, and sexual content in images and video, deepfake-style and likely cloned-voice manipulation, and abusive or threatening speech.
CodeGuard: scans AI-generated code for vulnerabilities in VS Code, Cursor, and Windsurf, detecting common CWE classes across Python, C/C++, and Java.
Security that meets the highest enterprise standards.


Built by the team that defined the category.
Our platform is engineered by the world’s leading experts in adversarial AI and machine learning.
100+
Proprietary research drives every technique, built in-house and exclusive to the Virtue AI Platform.
108
Our founding team ranks among the most impactful researchers in the field.
<48 Hours
Our breakthroughs quickly become your enterprise defenses, so you're always one step ahead.
Industry First
Analyze every agent action and block risky behavior with ultra-low latency.
Proof at scale.
VirtueGuard provides real-time guardrails for our chatbots and dialogue moderation, outperforming alternative solutions.

100+ Languages
Eliminate Blind Spots.
Secure inputs and outputs across text, audio, video, image, and code.
“The thoroughness of the reports is very impressive. Insights like these are helpful in evaluating safety trade-offs between different models, which is not trivial at all.”

1,000+
Risk Taxonomies Evaluated
Continuous API stress-testing across generative models.
Our collaboration with Virtue AI enables us to stay ahead of emerging threats by leveraging advanced capabilities that protect the firm, empower users, and safeguard our data—while helping us better serve our clients.

<10ms latency
Building Trustworthy AI for Finance
AllianceBernstein partnered with Virtue AI to bring advanced security to their generative AI systems.
Backed by cutting-edge research.
Stay ahead of the evolving threat landscape with our latest insights.

.png)
.png)
.jpg)

Stay in the loop.
Virtue AI brings control, governance, and resilience to enterprise AI.
Be the first to find out what's next.