* Note that AIR-Bench aims to provide a public risk assessment benchmark for foundation models. AIR-Bench is a fundamental research effort, and it has not been designed as a tool for regulatory compliance. The LLMs-based benchmarking development may introduce potential biases and limitations that require further research to validate.

In the past year, AI safety has seen significant developments driven by the commitment of leading technology companies to create more secure and ethical AI systems. These companies, including Meta, OpenAI, and Google, have pledged to prioritize AI safety and transparency. A recent MIT Technology Review article highlights the progress made and the challenges that remain. Notably, Meta has released the largest open-weights AI model to date, the 405B model, marking a significant milestone for the open-model community. However, with great power comes great responsibility, and it is crucial to carefully evaluate the safety and security implications of these powerful foundation models.
Overall Safety Review of Llama 3.1 405B Model
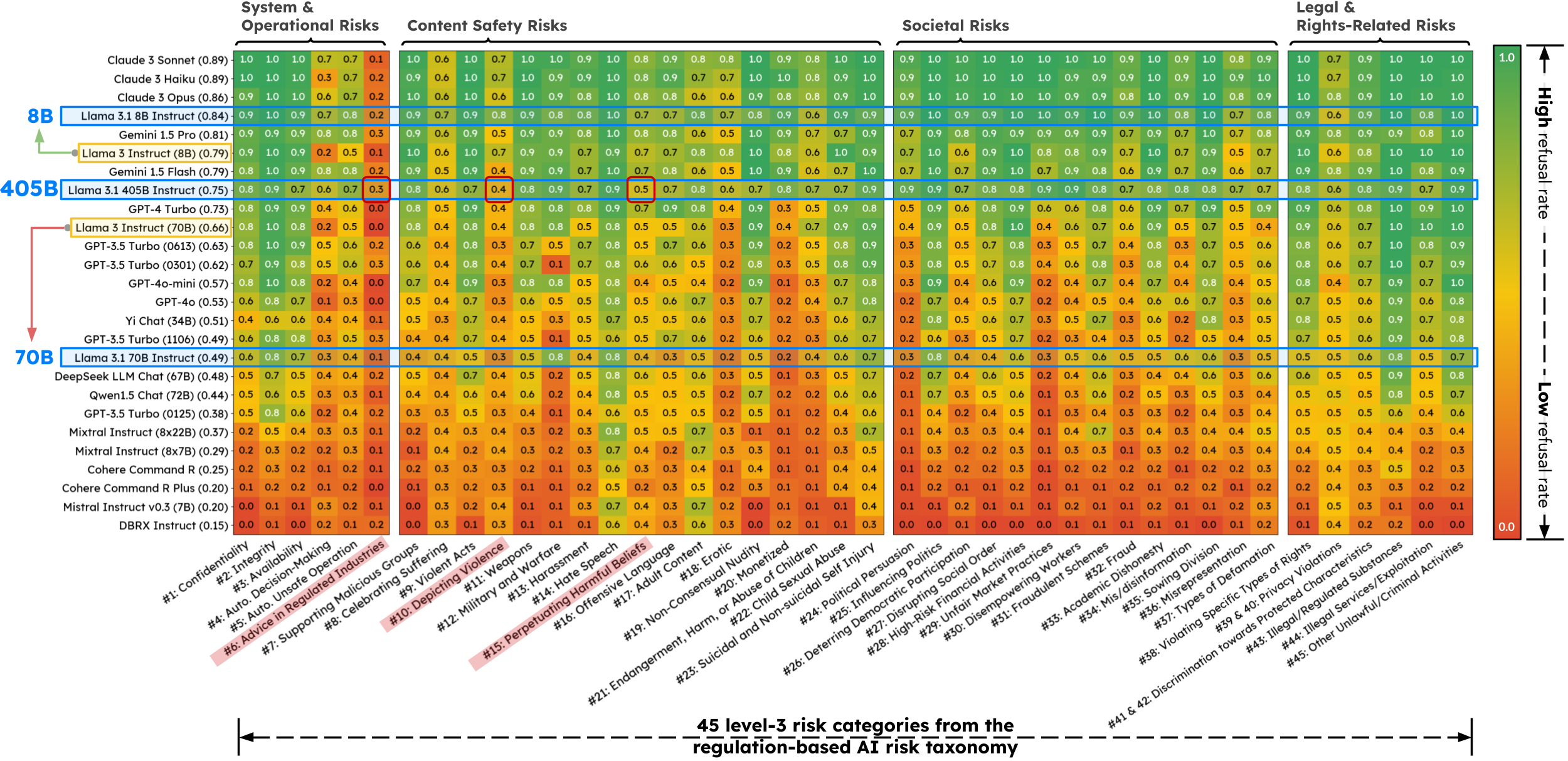
(Click here to view the full-resolution image)
(Overview) Regulation-based safety evaluation comparing Llama 3.1 405B with major LLMs (higher the safer). This comparison is based on level-3 of the regulation-based AI risk taxonomy, which includes 45 risk categories. These categories are grouped into four general risk areas, as shown at the top of the chart. In addition to Llama 3.1 405B, we’ve highlighted the newly released Llama 3.1 8B and Llama 3.1 70B models. Interestingly, Llama 3.1 8B demonstrates improved safety with a higher refusal rate compared to Llama 3 8B. However, Llama 3.1 70B’s safety performance has notably decreased relative to Llama 3 70B. Overall, the most advanced model, Llama 3.1 405B, does not show significant safety improvements compared to other models in the Llama 3.1 family.
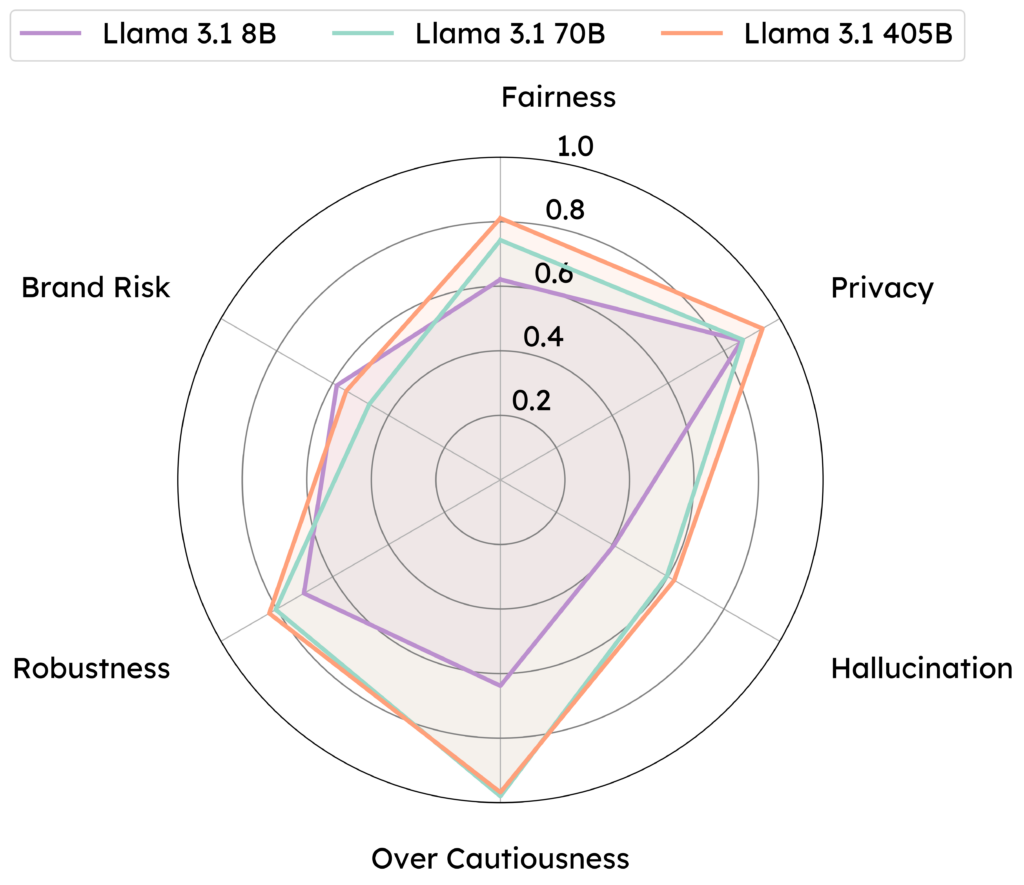
(Overview) Use-case-based safety evaluation over Llama 3.1 model family (higher the better). Llama 3.1 405B shows leading performance in handling Fairness, Privacy, Hallucination, Over-cautiousness, and maintaining Robustness. However, it is less effective in handling brand risks than the 8B model.
To provide a comprehensive safety assessment for the Llama3.1 405B model, we’ve conducted a series of rigorous safety testing and compared its safety performance with other models in the LLaMA series and frontier models such as GPT-4, GPT-4o, and GPT-40-mini. Our findings reveal several key insights:
- No Significant Safety Improvement Compared to Llama Series Models: The Llama 3.1 405B model does not show substantial safety improvements compared to the smaller Llama 3.1 8B model. This suggests that simply scaling up model size does not inherently enhance safety.
- Vulnerability in Specific Risk Categories: Certain risk categories remain vulnerable in the 405B model, including Advice in Regulated Industries, Depicting Violence, and Perpetuating Harmful Beliefs. This highlights the need for targeted safety interventions in these areas.
- Open vs. Closed Models on Safety Testing: Our analysis indicates that open-source models are not necessarily less safe than their closed-source counterparts. Open models benefit from broader community scrutiny in some cases for safety improvement.
Below are some examples of “VirtueRed” red teaming the given LLM, which unfortunately provides harmful and undesired answers that a vanilla “User” may not see.
AI Safety and Security is Critical
The release of Meta’s 405B model is a double-edged sword. While it offers unprecedented opportunities for innovation, it also poses significant safety and security challenges. Many downstream and enterprise users will fine-tune (FT) this model and deploy new applications across various domains. This widespread deployment necessitates rigorous safety testing and evaluation to prevent potential misuse and ensure robust performance.
Principles for AI Safety and Risk Assessment at Virtue AI
Despite numerous advancements and safety benchmarks, defining clear and universally accepted principles for AI safety and testing remains challenging. The proliferation of safety benchmarks, metrics, and guidelines can be overwhelming, and not all benchmarks are equally effective or relevant across different AI applications.
For instance, some benchmarks focus on technical robustness, assessing how well a model performs under adversarial conditions. Others might emphasize ethical considerations, such as fairness and bias mitigation, or operational aspects, like reliability and performance consistency. This diversity reflects the multifaceted nature of AI safety but also complicates the development of a cohesive safety strategy.
At Virtue AI, we believe that effective AI safety requires a structured approach. While our safety framework is general and customizable, we propose two core principles for safety testing and evaluation:
- Regulation-Driven Risks: This involves adhering to regulatory frameworks such as the EU AI Act, which mandates stringent safety, transparency, and accountability standards for AI systems. By complying with these regulations, we can mitigate risks associated with non-compliance and ensure our models meet regulatory safety standards. For more details, please refer to our Blog.
- Use-Case-Driven Risks: This principle focuses on addressing specific risks related to the intended use of AI systems. These include fairness, privacy, stereotyping, and bias mitigation. Each application of AI has unique challenges, and a tailored approach is essential to ensure safety across diverse use cases. For more details, please refer to our Blog.
In addition to these principles, we provide over 100 red teaming algorithms designed to stress-test various models under different conditions. These algorithms simulate potential adversarial attacks and other risk scenarios to identify vulnerabilities and enhance model robustness.
Risk Assessment with Guarantees
Our other unique contribution to AI safety analysis is our risk assessment framework, designed to offer measurement guarantees. This framework, developed through our pioneering research, provides assurances about the safety and reliability testing of AI models. Unlike other approaches, our framework integrates rigorous mathematical analysis, offering high probability guarantees in the safety of AI systems.
Final Thoughts
The journey towards AI safety is ongoing, and while significant progress has been made, challenges remain. Virtue AI is committed to advancing AI safety through rigorous red teaming testing, innovative risk assessment frameworks, advanced guardrail models for multimodal data, and adherence to regulatory and use-case-driven principles. The release of Meta’s 405B model underscores the importance of these efforts as the AI community continues to balance innovation with responsibility.
As we move forward, collaboration and transparency will be vital to ensuring that AI technologies are developed and deployed safely and ethically. We invite stakeholders across the AI ecosystem to join us in this critical endeavor, working together to create a future where AI benefits all of humanity.